Scrapy is a Python-based scraping and web crawling program available in Python Package Index. It means that you can install Scrapy on any operating system if you have pip installed.
Some operating systems provide Scrapy packages specific for their operating system, and version thus doesn't require pip for the installation.
However, these Scrapy packages usually are not as up-to-date as those distributed by pip though it's been better tested and integrated with the specific operating system and version.
Steps to install Scrapy using pip:
- Install pip for your operating system if you don't already have them installed.
Related: How to install pip on Ubuntu and Debian
Related: How to install pip on CentOS / Red Hat / FedoraRelated: Installation - pip documentation
- Install scrapy package using pip.
user@host:~$ pip3 install scrapy Collecting scrapy Downloading Scrapy-2.5.1-py2.py3-none-any.whl (254 kB) |████████████████████████████████| 254 kB 6.1 MB/s Collecting cssselect>=0.9.1 Downloading cssselect-1.1.0-py2.py3-none-any.whl (16 kB) Requirement already satisfied: cryptography>=2.0 in /usr/lib/python3/dist-packages (from scrapy) (3.3.2) Collecting lxml>=3.5.0 Downloading lxml-4.7.1-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.manylinux_2_24_aarch64.whl (6.6 MB) |████████████████████████████████| 6.6 MB 52.3 MB/s ##### snipped Installing collected packages: attrs, zope.interface, w3lib, typing-extensions, pyasn1, lxml, incremental, hyperlink, hyperframe, hpack, cssselect, constantly, Automat, Twisted, pyasn1-modules, priority, parsel, jmespath, itemadapter, h2, service-identity, queuelib, PyDispatcher, protego, itemloaders, scrapy WARNING: The script automat-visualize is installed in '/home/user/.local/bin' which is not on PATH. Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location. WARNING: The scripts cftp, ckeygen, conch, mailmail, pyhtmlizer, tkconch, trial, twist and twistd are installed in '/home/user/.local/bin' which is not on PATH. Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location. WARNING: The script scrapy is installed in '/home/user/.local/bin' which is not on PATH. Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location. Successfully installed Automat-20.2.0 PyDispatcher-2.0.5 Twisted-21.7.0 attrs-21.4.0 constantly-15.1.0 cssselect-1.1.0 h2-3.2.0 hpack-3.0.0 hyperframe-5.2.0 hyperlink-21.0.0 incremental-21.3.0 itemadapter-0.4.0 itemloaders-1.0.4 jmespath-0.10.0 lxml-4.7.1 parsel-1.6.0 priority-1.3.0 protego-0.1.16 pyasn1-0.4.8 pyasn1-modules-0.2.8 queuelib-1.6.2 scrapy-2.5.1 service-identity-21.1.0 typing-extensions-4.0.1 w3lib-1.22.0 zope.interface-5.4.0The installation notes mentions the installation directory, which in this case is /home/user/.local/bin and if the directory is within the PATH environment variable which is where your operating system will look for the program if you run the program without specifying the full path.
- Run scrapy using full path.
$ /home/user/.local/bin/scrapy Scrapy 2.5.1 - no active project Usage: scrapy <command> [options] [args] Available commands: bench Run quick benchmark test commands fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values shell Interactive scraping console startproject Create new project version Print Scrapy version view Open URL in browser, as seen by Scrapy [ more ] More commands available when run from project directory Use "scrapy <command> -h" to see more info about a command
- Add pip installation directory to PATH environment variable.
$ echo PATH=$PATH:/home/user/.local/bin >> ~/.bashrc #Linux
- Start a new terminal session to quickly load the new PATH environment variable.
$ bash
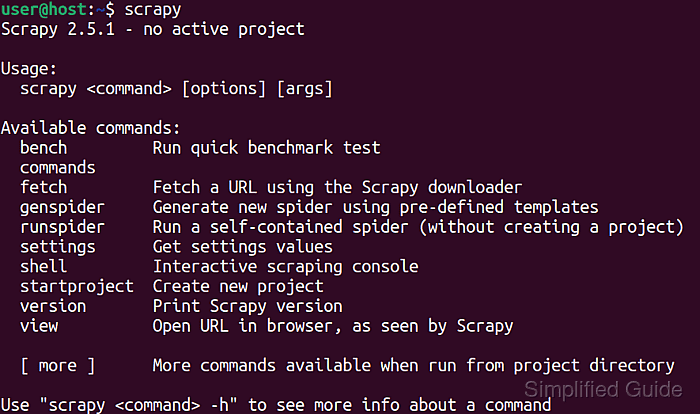
- Run scrapy again without specifying full path.
$ scrapy Scrapy 2.5.1 - no active project Usage: scrapy <command> [options] [args] Available commands: bench Run quick benchmark test commands fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values shell Interactive scraping console startproject Create new project version Print Scrapy version view Open URL in browser, as seen by Scrapy [ more ] More commands available when run from project directory Use "scrapy <command> -h" to see more info about a command


Mohd Shakir Zakaria is a cloud architect with deep roots in software development and open-source advocacy. Certified in AWS, Red Hat, VMware, ITIL, and Linux, he specializes in designing and managing robust cloud and on-premises infrastructures.




Comment anonymously. Login not required.