The typical way of presenting data on websites is using an HTML table, and Scrapy is perfect for the job.
An HTML table starts with a table tag, with each row defined with tr and a column with td tag. Optionally, thead is used to group the header rows and tbody to group the content rows.

To scrape data from an HTML table, we need to find the table that we're interested in on a website and iterate for each row the columns that we want to get our data from.
Related: HTML Tables guide
Steps to scrape HTML table using Scrapy:
- Go to the web page that you want to scrape the table data from using your web browser.
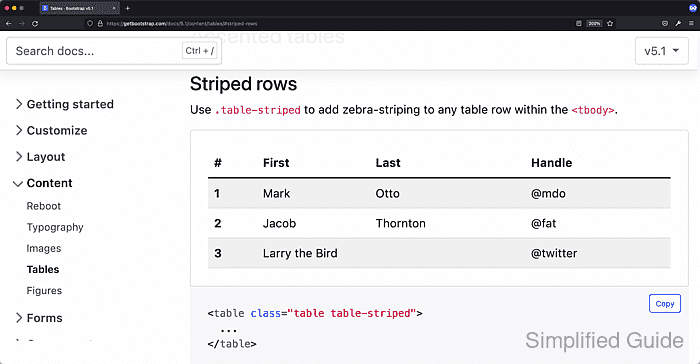
For this example we're to scrape Bootstrap's Table documentation page
- Inspect the element of the table using your browser's built-in developer tools or by viewing the source code.
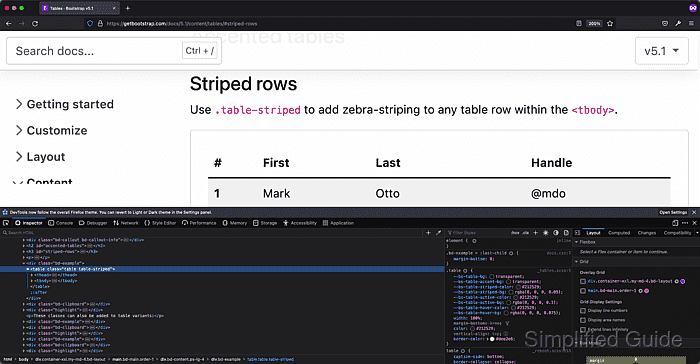
In this case, the table is assigned the classes of table and table-striped Here's the actual HTML code for the table
<table class="table table-striped"> <thead> <tr> <th scope="col">#</th> <th scope="col">First</th> <th scope="col">Last</th> <th scope="col">Handle</th> </tr> </thead> <tbody> <tr> <th scope="row">1</th> <td>Mark</td> <td>Otto</td> <td>@mdo</td> </tr> <tr> <th scope="row">2</th> <td>Jacob</td> <td>Thornton</td> <td>@fat</td> </tr> <tr> <th scope="row">3</th> <td colspan="2">Larry the Bird</td> <td>@twitter</td> </tr> </tbody> </table>
- Launch Scrapy shell at the terminal with the web page URL as an argument.
$ scrapy shell https://getbootstrap.com/docs/5.1/content/tables/#striped-rows 2022-02-02 07:17:47 [scrapy.utils.log] INFO: Scrapy 2.5.1 started (bot: scrapybot) 2022-02-02 07:17:47 [scrapy.utils.log] INFO: Versions: lxml 4.7.1.0, libxml2 2.9.12, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 21.7.0, Python 3.9.7 (default, Sep 10 2021, 14:59:43) - [GCC 11.2.0], pyOpenSSL 20.0.1 (OpenSSL 1.1.1l 24 Aug 2021), cryptography 3.3.2, Platform Linux-5.13.0-27-generic-aarch64-with-glibc2.34 2022-02-02 07:17:47 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.epollreactor.EPollReactor 2022-02-02 07:17:47 [scrapy.crawler] INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0} ##### snipped - Check HTTP response code to see if the request was successful.
In [1]: response Out[1]: <200 https://getbootstrap.com/docs/5.1/content/tables/>
200 is the OK success respond status code for HTTP.
- Search for the table you're interested in using the xpath selector.
In [2]: table = response.xpath('//*[@class="table table-striped"]') In [3]: table Out[3]: [<Selector xpath='//*[@class="table table-striped"]' data='<table class="table table-striped">\n ...'>]In this case the table is assigned table table-striped CSS classes and that's what we use as our selector.
- Narrow down search to tbody if applicable.
In [4]: table = response.xpath('//*[@class="table table-striped"]//tbody') In [5]: table Out[5]: [<Selector xpath='//*[@class="table table-striped"]//tbody' data='<tbody>\n <tr>\n <th scope="row...'>] - Get the table rows by searching for tr.
In [6]: rows = table.xpath('//tr') In [7]: rows Out[7]: [<Selector xpath='//tr' data='<tr>\n <th scope="col">#</th>\n ...'>, <Selector xpath='//tr' data='<tr>\n <th scope="row">1</th>\n ...'>, <Selector xpath='//tr' data='<tr>\n <th scope="row">2</th>\n ...'>, <Selector xpath='//tr' data='<tr>\n <th scope="row">3</th>\n ...'>, ##### snipped - Select a row to test.
In [8]: row = rows[2]
Multiple rows are stored as an array.
- Access the row's column via the <td> selector and extract column's data.
In [9]: row.xpath('td//text()')[0].extract() Out[9]: 'Jacob'The first column uses <th> instead of <td> thus our array index starts at the First column of the table.
- Combine everything into a complete code by iterating each rows with a for loop.
In [10]: for row in response.xpath('//*[@class="table table-striped"]//tbody//tr'): ...: name = { ...: 'first' : row.xpath('td[1]//text()').extract_first(), ...: 'last': row.xpath('td[2]//text()').extract_first(), ...: 'handle' : row.xpath('td[3]//text()').extract_first(), ...: } ...: print(name) ...: {'first': 'Mark', 'last': 'Otto', 'handle': '@mdo'} {'first': 'Jacob', 'last': 'Thornton', 'handle': '@fat'} {'first': 'Larry the Bird', 'last': '@twitter', 'handle': None} - Create a Scrapy spider from the previous codes (optional).
- scrape-table.py
import scrapy class ScrapeTableSpider(scrapy.Spider): name = 'scrape-table' allowed_domains = ['https://getbootstrap.com/docs/4.0/content/tables'] start_urls = ['http://https://getbootstrap.com/docs/4.0/content/tables/'] def start_requests(self): urls = [ 'https://getbootstrap.com/docs/4.0/content/tables', ] for url in urls: yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): for row in response.xpath('//*[@class="table table-striped"]//tbody/tr'): yield { 'first' : row.xpath('td[1]//text()').extract_first(), 'last': row.xpath('td[2]//text()').extract_first(), 'handle' : row.xpath('td[3]//text()').extract_first(), }
Related: How to create a Scrapy spider
- Run the spider with JSON output.
$ scrapy crawl --nolog --output -:json scrape-table [ {"first": "Mark", "last": "Otto", "handle": "@mdo"}, {"first": "Jacob", "last": "Thornton", "handle": "@fat"}, {"first": "Larry the Bird", "last": "@twitter", "handle": null}


Mohd Shakir Zakaria is a cloud architect with deep roots in software development and open-source advocacy. Certified in AWS, Red Hat, VMware, ITIL, and Linux, he specializes in designing and managing robust cloud and on-premises infrastructures.




Comment anonymously. Login not required.