RSS is designed for applications to access websites in an easily readable format. Users could then use these applications to access these websites programmatically.
RSS contains snippets of the latest website content in standardized XML format. Therefore, it is one of the best ways for a web scraper such as Scrapy to get the latest website update.
News sites and blogs usually provide RSS feed that is linked to using the official RSS icon.
![]()
You can monitor when a website is updated and get the latest content by scraping the RSS feed using Scrapy.
Steps to scrape RSS feed using Scrapy:
- Navigate to the site via web browser and search for RSS feed link or icon.
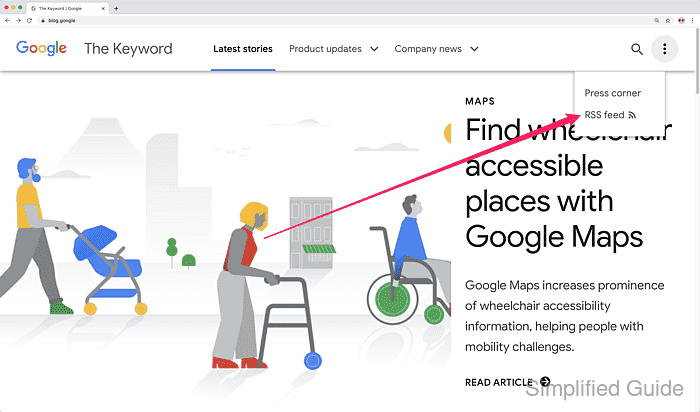
- Click on the RSS link to view and examine the RSS feed.
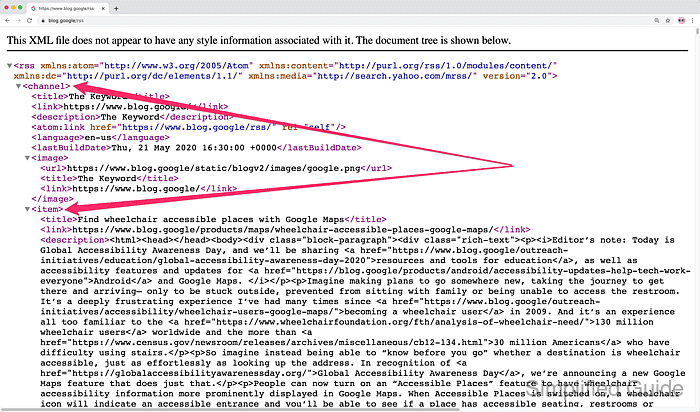
Notice that it's basically an XML document. Blog posts are in channel→item elements.
- Open Scrapy shell at the command line with the RSS feed URL as an argument.
$ scrapy shell https://www.blog.google/rss 2022-01-23 06:48:39 [scrapy.utils.log] INFO: Scrapy 2.5.1 started (bot: scrapybot) 2022-01-23 06:48:39 [scrapy.utils.log] INFO: Versions: lxml 4.7.1.0, libxml2 2.9.12, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 21.7.0, Python 3.9.7 (default, Sep 10 2021, 14:59:43) - [GCC 11.2.0], pyOpenSSL 20.0.1 (OpenSSL 1.1.1l 24 Aug 2021), cryptography 3.3.2, Platform Linux-5.13.0-27-generic-aarch64-with-glibc2.34 2022-01-23 06:48:39 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.epollreactor.EPollReactor 2022-01-23 06:48:39 [scrapy.crawler] INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0} ##### snipped - Check HTTP response status and make sure it returns 200.
>>> response <200 https://www.blog.google/rss/>
- Search for blog posts with XPath based on the structure.
>>> posts = response.xpath('//channel/item') - Check returned item count to confirm.
>>>> len(posts) 20
- Extract an element from the first and last item to test.
>>> posts[0].xpath('title/text()').extract() ['AG Paxton’s false claims still don’t add up'] >>> posts[19].xpath('title/text()').extract() ['Career certificates for Singapore’s future economy'] - Iterate through each item to get all required data.
>>> for item in response.xpath('//channel/item'): ... post = { ... 'title' : item.xpath('title//text()').extract_first(), ... 'link': item.xpath('link//text()').extract_first(), ... 'pubDate' : item.xpath('pubDate//text()').extract_first(), ... } ... print(post) ... {'title': 'AG Paxton’s false claims still don’t add up', 'link': 'https://blog.google/outreach-initiatives/public-policy/ag-paxtons-false-claims-still-dont-add-up/', 'pubDate': 'Fri, 21 Jan 2022 17:00:00 +0000'} {'title': 'XWP helps publishers get creative using Web Stories', 'link': 'https://blog.google/google-for-creators/xwp-helps-publishers-get-creative-using-web-stories/', 'pubDate': 'Thu, 20 Jan 2022 19:00:00 +0000'} {'title': 'From Lagos to London, this marketer is making an impact', 'link': 'https://blog.google/inside-google/life-at-google/lagos-london-marketer-making-impact/', 'pubDate': 'Thu, 20 Jan 2022 17:00:00 +0000'} {'title': 'Your 2022 guide to Google Ad Manager', 'link': 'https://blog.google/products/admanager/2022-guide-google-ad-manager/', 'pubDate': 'Thu, 20 Jan 2022 13:00:00 +0000'} {'title': 'Surfacing women in science with the Smithsonian', 'link': 'https://blog.google/outreach-initiatives/arts-culture/surfacing-women-science-smithsonian/', 'pubDate': 'Wed, 19 Jan 2022 14:00:00 +0000'} {'title': 'It’s time for a new EU-US data transfer framework', 'link': 'https://blog.google/around-the-globe/google-europe/its-time-for-a-new-eu-us-data-transfer-framework/', 'pubDate': 'Wed, 19 Jan 2022 11:00:00 +0000'} {'title': 'The harmful consequences of Congress’s anti-tech bills', 'link': 'https://blog.google/outreach-initiatives/public-policy/the-harmful-consequences-of-congresss-anti-tech-bills/', 'pubDate': 'Tue, 18 Jan 2022 20:00:00 +0000'} {'title': "This year's Doodle for Google contest is all about self care", 'link': 'https://blog.google/inside-google/doodles/doodle-for-google-2022/', 'pubDate': 'Tue, 18 Jan 2022 16:00:00 +0000'} {'title': 'The biggest lesson from a local news startup: listen', 'link': 'https://blog.google/outreach-initiatives/google-news-initiative/the-beacon/', 'pubDate': 'Tue, 18 Jan 2022 14:00:00 +0000'} {'title': 'Schneider Electric secures its teams through Android Enterprise', 'link': 'https://blog.google/products/android-enterprise/schneiderelectric/', 'pubDate': 'Tue, 18 Jan 2022 11:00:00 +0000'} {'title': 'So you got new gear for the holidays. Now what?', 'link': 'https://blog.google/products/devices-services/google-products-setup-tips/', 'pubDate': 'Fri, 14 Jan 2022 19:58:00 +0000'} {'title': 'This talking Doogler deserves a round of a-paws', 'link': 'https://blog.google/inside-google/googlers/talking-doogler-deserves-round-paws/', 'pubDate': 'Fri, 14 Jan 2022 16:00:00 +0000'} {'title': 'Increasing Google’s investment in the UK', 'link': 'https://blog.google/around-the-globe/google-europe/increasing-googles-investment-in-the-uk/', 'pubDate': 'Fri, 14 Jan 2022 06:00:00 +0000'} {'title': 'Some facts about Google Analytics data privacy', 'link': 'https://blog.google/around-the-globe/google-europe/google-analytics-facts/', 'pubDate': 'Thu, 13 Jan 2022 19:48:00 +0000'} {'title': 'Making Open Source software safer and more secure', 'link': 'https://blog.google/technology/safety-security/making-open-source-software-safer-and-more-secure/', 'pubDate': 'Thu, 13 Jan 2022 18:45:00 +0000'} {'title': 'Advancing genomics to better understand and treat disease', 'link': 'https://blog.google/technology/health/advancing-genomics-better-understand-and-treat-disease/', 'pubDate': 'Thu, 13 Jan 2022 17:00:00 +0000'} {'title': 'How dreaming big and daring to fail led Chai to Google', 'link': 'https://blog.google/inside-google/life-at-google/how-dreaming-big-and-daring-fail-led-chai-google/', 'pubDate': 'Thu, 13 Jan 2022 16:00:00 +0000'} {'title': 'Celebrating a decade of partnering with Technovation', 'link': 'https://blog.google/outreach-initiatives/education/celebrating-decade-partnering-technovation/', 'pubDate': 'Wed, 12 Jan 2022 18:00:00 +0000'} {'title': 'Start the year strong with Google Marketing Platform', 'link': 'https://blog.google/products/marketingplatform/360/start-year-strong-google-marketing-platform/', 'pubDate': 'Wed, 12 Jan 2022 16:00:00 +0000'} {'title': 'Career certificates for Singapore’s future economy', 'link': 'https://blog.google/around-the-globe/google-asia/career-certificates-singapore/', 'pubDate': 'Wed, 12 Jan 2022 04:00:00 +0000'}Blog content is in the description element but not shown in our example as it's too lengthy to show here.
- Create a Scrapy spider based on the previous shell process (optional).
- scrape-rss.py
import scrapy class ScrapeRssSpider(scrapy.Spider): name = 'scrape-rss' allowed_domains = ['https://www.blog.google/rss'] start_urls = ['http://https://www.blog.google/rss/'] def start_requests(self): urls = [ 'https://www.blog.google/rss', ] for url in urls: yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): for post in response.xpath('//channel/item'): yield { 'title' : post.xpath('title//text()').extract_first(), 'link': post.xpath('link//text()').extract_first(), 'pubDate' : post.xpath('pubDate//text()').extract_first(), }
Related: How to create a Scrapy spider
- Test Scrapy spider to see if it works.
$ scrapy crawl --nolog --output -:json scrape-rss [ {"title": "AG Paxton\u2019s false claims still don\u2019t add up", "link": "https://blog.google/outreach-initiatives/public-policy/ag-paxtons-false-claims-still-dont-add-up/", "pubDate": "Fri, 21 Jan 2022 17:00:00 +0000"}, {"title": "XWP helps publishers get creative using Web Stories", "link": "https://blog.google/google-for-creators/xwp-helps-publishers-get-creative-using-web-stories/", "pubDate": "Thu, 20 Jan 2022 19:00:00 +0000"}, {"title": "From Lagos to London, this marketer is making an impact", "link": "https://blog.google/inside-google/life-at-google/lagos-london-marketer-making-impact/", "pubDate": "Thu, 20 Jan 2022 17:00:00 +0000"}, {"title": "Your 2022 guide to Google Ad Manager", "link": "https://blog.google/products/admanager/2022-guide-google-ad-manager/", "pubDate": "Thu, 20 Jan 2022 13:00:00 +0000"}, {"title": "Surfacing women in science with the Smithsonian", "link": "https://blog.google/outreach-initiatives/arts-culture/surfacing-women-science-smithsonian/", "pubDate": "Wed, 19 Jan 2022 14:00:00 +0000"}, {"title": "It\u2019s time for a new EU-US data transfer framework", "link": "https://blog.google/around-the-globe/google-europe/its-time-for-a-new-eu-us-data-transfer-framework/", "pubDate": "Wed, 19 Jan 2022 11:00:00 +0000"}, {"title": "The harmful consequences of Congress\u2019s anti-tech bills", "link": "https://blog.google/outreach-initiatives/public-policy/the-harmful-consequences-of-congresss-anti-tech-bills/", "pubDate": "Tue, 18 Jan 2022 20:00:00 +0000"}, {"title": "This year's Doodle for Google contest is all about self care", "link": "https://blog.google/inside-google/doodles/doodle-for-google-2022/", "pubDate": "Tue, 18 Jan 2022 16:00:00 +0000"}, {"title": "The biggest lesson from a local news startup: listen", "link": "https://blog.google/outreach-initiatives/google-news-initiative/the-beacon/", "pubDate": "Tue, 18 Jan 2022 14:00:00 +0000"}, {"title": "Schneider Electric secures its teams through Android Enterprise", "link": "https://blog.google/products/android-enterprise/schneiderelectric/", "pubDate": "Tue, 18 Jan 2022 11:00:00 +0000"}, {"title": "So you got new gear for the holidays. Now what?", "link": "https://blog.google/products/devices-services/google-products-setup-tips/", "pubDate": "Fri, 14 Jan 2022 19:58:00 +0000"}, {"title": "This talking Doogler deserves a round of a-paws", "link": "https://blog.google/inside-google/googlers/talking-doogler-deserves-round-paws/", "pubDate": "Fri, 14 Jan 2022 16:00:00 +0000"}, {"title": "Increasing Google\u2019s investment in the UK", "link": "https://blog.google/around-the-globe/google-europe/increasing-googles-investment-in-the-uk/", "pubDate": "Fri, 14 Jan 2022 06:00:00 +0000"}, {"title": "Some facts about Google Analytics data privacy", "link": "https://blog.google/around-the-globe/google-europe/google-analytics-facts/", "pubDate": "Thu, 13 Jan 2022 19:48:00 +0000"}, {"title": "Making Open Source software safer and more secure", "link": "https://blog.google/technology/safety-security/making-open-source-software-safer-and-more-secure/", "pubDate": "Thu, 13 Jan 2022 18:45:00 +0000"}, {"title": "Advancing genomics to better understand and treat disease", "link": "https://blog.google/technology/health/advancing-genomics-better-understand-and-treat-disease/", "pubDate": "Thu, 13 Jan 2022 17:00:00 +0000"}, {"title": "How dreaming big and daring to fail led Chai to Google", "link": "https://blog.google/inside-google/life-at-google/how-dreaming-big-and-daring-fail-led-chai-google/", "pubDate": "Thu, 13 Jan 2022 16:00:00 +0000"}, {"title": "Celebrating a decade of partnering with Technovation", "link": "https://blog.google/outreach-initiatives/education/celebrating-decade-partnering-technovation/", "pubDate": "Wed, 12 Jan 2022 18:00:00 +0000"}, {"title": "Start the year strong with Google Marketing Platform", "link": "https://blog.google/products/marketingplatform/360/start-year-strong-google-marketing-platform/", "pubDate": "Wed, 12 Jan 2022 16:00:00 +0000"}, {"title": "Career certificates for Singapore\u2019s future economy", "link": "https://blog.google/around-the-globe/google-asia/career-certificates-singapore/", "pubDate": "Wed, 12 Jan 2022 04:00:00 +0000"} ]


Mohd Shakir Zakaria is a cloud architect with deep roots in software development and open-source advocacy. Certified in AWS, Red Hat, VMware, ITIL, and Linux, he specializes in designing and managing robust cloud and on-premises infrastructures.




Comment anonymously. Login not required.